CPU Caches


Have you ever bought a bunch of stamps so you don't have to go to the post office every time you need to mail a letter? Caches are like that, but for computers. Instead of stamps, they store copies of the data that your computer uses most often.
Why do we need caches?
We need caches to improve the performance of applications and systems. Caches store copies of frequently accessed data in a faster memory so that the CPU can access it more quickly. This can significantly reduce the amount of time it takes for applications to load and respond to user input.
Most modern computers have multiple levels of cache, including L1, L2, and L3 caches. L1 cache is the closest to the CPU, followed by the L2 cache, and finally the L3 cache. Each CPU core has its own dedicated L1 cache, while the L3 cache is shared by all cores.
Caches on my Linux desktop:
$ lscpu -C
NAME ONE-SIZE ALL-SIZE WAYS TYPE LEVEL SETS PHY-LINE COHERENCY-SIZE
L1d 48K 512K 12 Data 1 64 1 64
L1i 32K 512K 8 Instruction 1 64 1 64
L2 1.3M 12M 10 Unified 2 2048 1 64
L3 25M 25M 10 Unified 3 40960 1 64
Applications also use caches to avoid requesting data from a remote data source, which is typically more expensive than accessing data from a local in-memory cache.
Each item in a cache has two parts: a key and a value. The key is used to identify the item, and the value is the actual data. If the value for a given key is found in the cache, it is considered a "cache hit." Otherwise, it is a "cache miss."
Here is a simple example of a cache:
Cache:
Key: "user_id"
Value: 1234567890
If the application needs to access the user's ID, it can first check the cache. If the key "user_id" is found in the cache, the application can retrieve the value (1234567890) directly from the cache, without having to access the data source. This is a cache hit.
However, if the key "user_id" is not found in the cache, the application must access the data source to retrieve the value. This is a cache miss.
Caches can significantly improve the performance of applications by reducing the number of times the application needs to access the slower main memory or data source.
Now that we have covered the basics, let's explore some cache design ideas.
Cache design thought experiment
Imagine how CPU caches must have been designed. What challenges did the engineers face? What trade-offs did they have to make?
Memory is represented as an array of bytes. A cache is simply a faster memory that stores copies of frequently accessed data to reduce the need to retrieve it from the slower main memory (RAM). A simple way to picture a cache is as a list of key-value pairs, where the key is the address of the byte and the value is the byte itself.
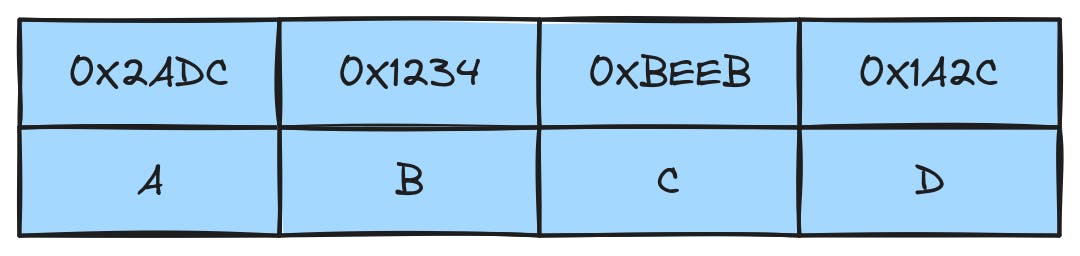
If caches were designed this way, the CPU would have to do a lot of work to locate the address it is interested in, or additional hardware would be needed to optimize the lookups. That makes the cache either slow or very expensive.
Locality of reference
Caches are small and fast, but expensive compared to main memory. Programs often reuse the same data repeatedly over a short period of time (`temporal locality`), or access data that is located near other data that has been recently accessed (`spatial locality`).
Consider the following example that calculates the sum of a list of numbers:
int sum = 0;
for (int i = 0; i < n; i++)
sum += nums[i];
In this example, the variables sum and i are accessed throughout the loop, while the elements of the array nums are accessed sequentially. This means that the program exhibits both temporal and spatial locality.
Exploit the locality of reference
Caches exploit locality of reference by fetching memory in blocks (aka cache lines). The bytes in a cache line are contiguous, so they can be addressed using a base address and an offset. The base address is the address of the first byte in the cache line, and the offset is the number of bytes from the base address to the desired byte.

The above image uses a cache line of 4 bytes. The last 2 bits in the address can be used to locate a byte within the cache line. To find the matching cache line, the CPU would still have to do a lot of work or use additional hardware to optimize it. When the cache is full, replacement policies like LRU, LFU, or random are used to free up space for the new cache line.
Caches using this design are called "fully associative caches". The base address is referred to as "cache tag".
Improve cache line lookups
It is difficult to quickly find a cache line in a fully associative cache. How about using a few least significant bits in the base address (aka "cache tag") as a hash? The hash is always used to locate the cache line to read and write to.

Caches using this design are called "direct-mapped caches". The above image is a 32-bytes direct-mapped cache with 8 cache lines of 4-bytes each. This design makes it easy to find the corresponding cache line and the byte within the cache line. However, what if multiple cache lines map to the same cache address (similar to a hash collision)? Well, it is treated as a cache miss and the new cache line is fetched and stored in the address.
This design can suffer from thrashing when multiple cache lines map to the same address. The cache line is constantly being replaced, which can lead to poor performance.
Balancing the trade-offs
Finding a cache line in a "fully associative" cache is expensive, while "direct-mapped" cache suffers from thrashing. To address these drawbacks, caches can be split into multiple sets. Each set can be located directly, but finding the cache line within the set requires more work from the CPU or use additional hardware to optimize it.
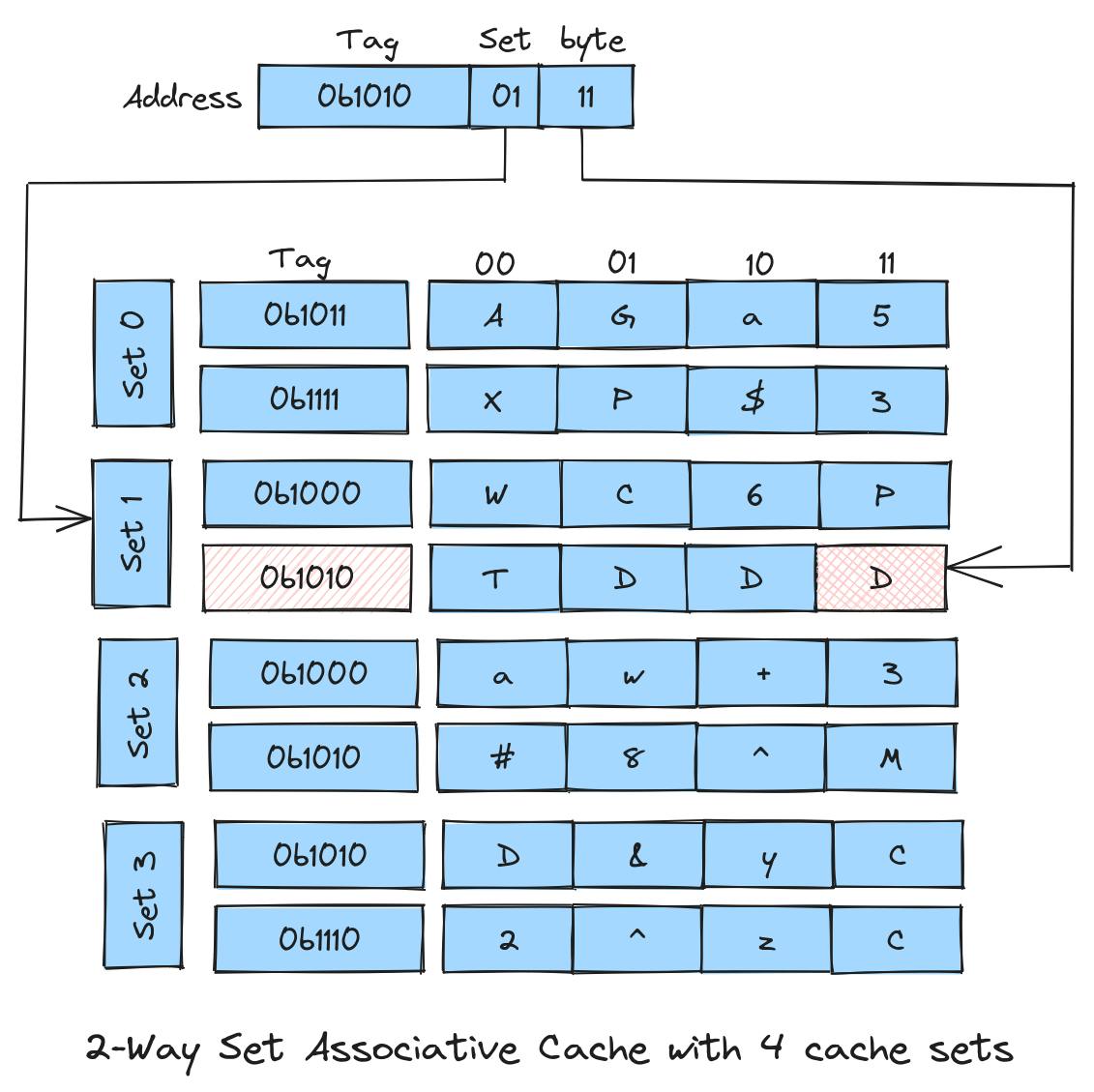
The image above shows a cache with 4 sets (using 2-bits), and with 2 cache lines in each set. Caches using this design are called "set associative caches." Since each set has 2 cache lines, this is a 2-way set associative cache. If each set were to have 4 cache lines, that would be a 4-way set associative cache.
To find a cache line in a set associative cache, the CPU maps the address to the corresponding set and searches for the tag within that set. This search is limited to the set, rather than the entire cache as in a fully associative cache. Similarly, when multiple cache lines map to the same set, the CPU can use any of the free slot, as long as there is space in the set.
Wrap Up
Most modern computers today have multiple levels of caches. They improve the performance of applications and systems. Most of them are "set associative caches". Memory is always fetched in blocks called "cache lines".
I hope that after reading this post, you will be able to understand most of the details of the output of the lscpu -C command the next time you run it.